

Motivation
Programmers tend to use strongly typed languages for the safety in the runtime and their own comfort while developing applications. While using new dependency, they often have to browse the documentation by symbolic names of classes and functions. Oftentimes, they don’t know the function name, but are convinced there must be a function somewhere that fits given type transformation. In this talk, we will focus on a prototype tool that lets you browse the docs using types as search keys in Kotlin.
Once in a while every developer stumbles upon a code like this:
val list = listOf("Andrzej", "Filip", "Michał")
return Pair(
list.filter { it.length <= 5 },
list.filter { it.length > 5 }
)
And then a thought comes in. This looks like something people might do a lot. It surely can be done in a shorter, more readable way. So, what do we know that can help us refactor this code? Well in order to replace this Pair(list.filter(...), list.filter(...)) we want a function that behaves like this:
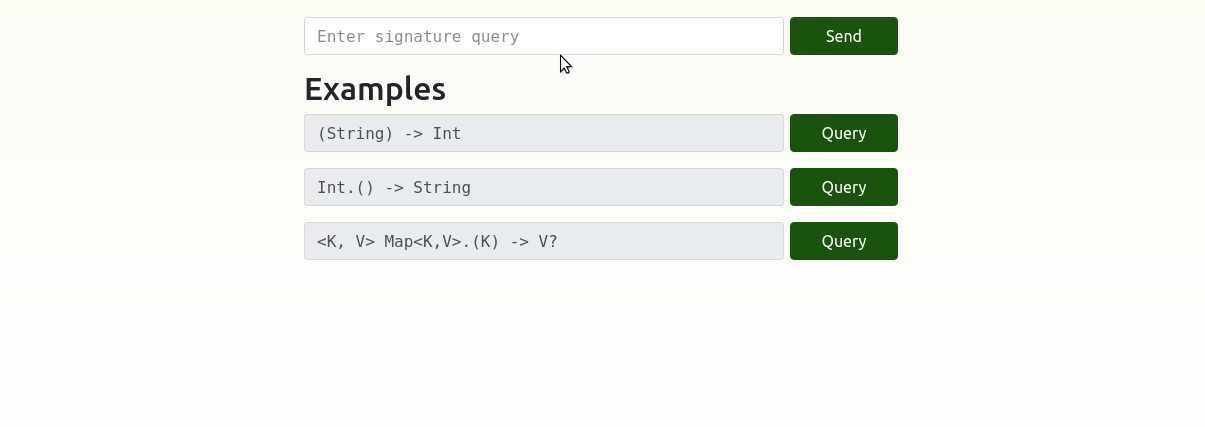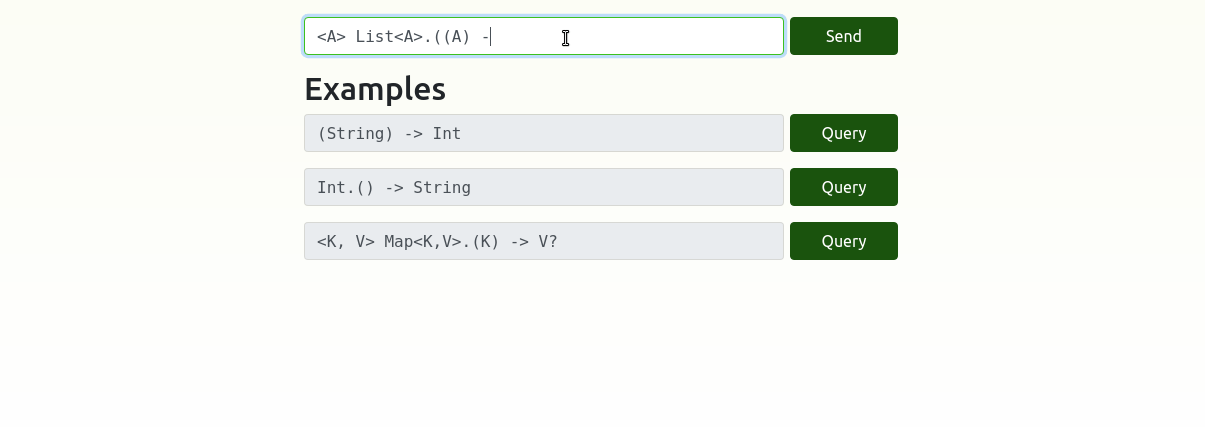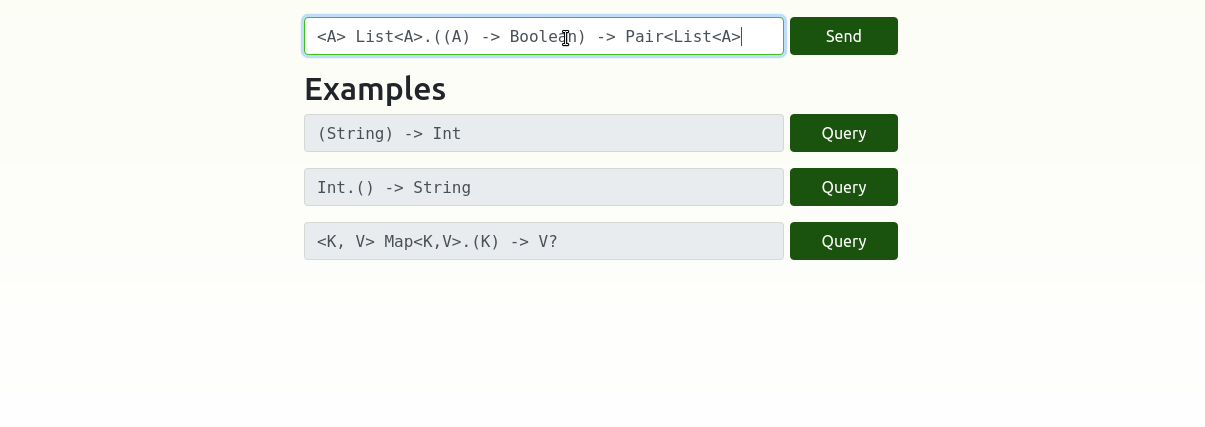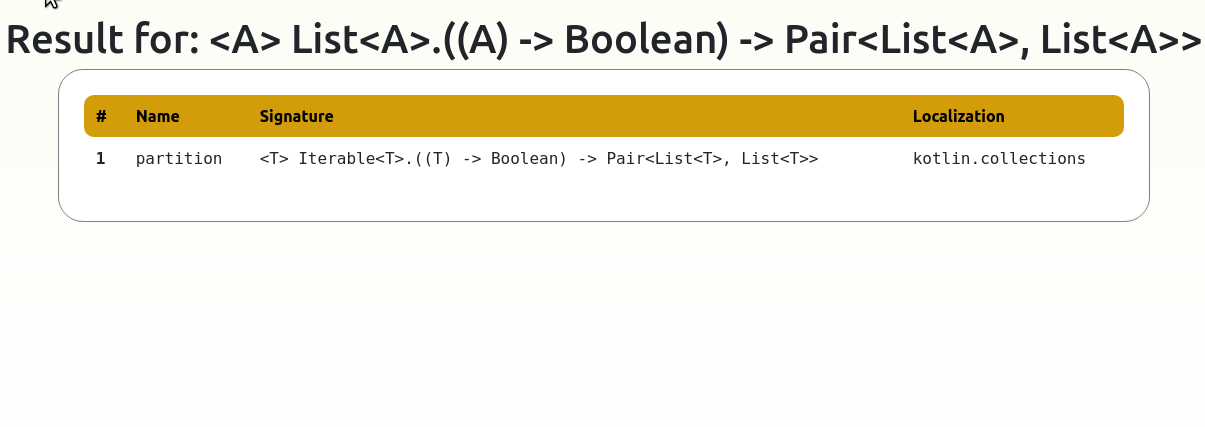
<T> List<T>.((T) -> Boolean) -> Pair<List<T>, List<T>>
Ok, that’s great, but we still are pretty much nowhere. And that’s because we need this function’s name to call it. How would we conventionally do it? Well, we could use Dokka for stdlib and look through potential functions, but that can take a lot of time. Plus it is way too close to actual work and we (software developers) don’t really like that. That’s where Inkuire comes in. Inkuire lets us search a library documentation with function signatures as search keys.
Oooo, by the way the function we are looking for is partition.

Why Scala for Kotlin tooling?
One can wonder: Why are you using Scala for Kotlin tooling? Those are actually two questions framed as one:
- “Why for Kotlin?” - This one is really simple. As software developers we don’t really like doing too much work. In case of gathering Kotlin source data, dokka can do a huge share of work for us. We just need to format the data and persist it. Additionally Kotlin has a way simpler type system than Scala (especially Scala3). Therefore, having Hoogle for Kotlin is like proof of concept for having a similar tool in Scala3 world.
- “Why in Scala?” - The first reason is that Scala is a more mature language. Scala.js has better support and documentation than Kotlin/JS. The other reason is just our personal preference. Scala with the use of Cats and similar libraries allows us to write code in a more functional way and probably everyone can agree, that is the 2020 way to code.
Gathering code data
First of all, we need a lot of data about code. It’s not plain data from source code but rather complete information about types provided by Kotlin compiler. Therefore we have to analyse sources before we can serialize them. Of course we could use descriptors analysis offered by JetBrains, but there is a more convenient way of doing that thanks to the recently released documentation tool - dokka. You can find out more about dokka here, but what you have to know is its powerful pluggability abilities that enable you to have all required data about Kotlin and Java sources enclosed in a very simple and intuitive API. If you would like to use dokka to analyse your own sources, check out this great article by Marcin Aman.
Actual search
Once we have the data, it’s time to use it to find our mystery function. The first thing we have to worry about is how to tell the engine what we want, in other words: what should be the format of the query. After reading the title and motivation, it shouldn’t come as a surprise, that we want to search for a function with a specific signature, so our input is just going to be a Kotlin signature.
The first step in processing an input string is parsing the given text with a grammar that recognises Kotlin function signatures and then map it to our model. Ironically, searching through scala-parser-combinators with signatures as search keys would be really helpful, since the most commonly used functions from this library are: ^^, ~, ~>, |, <~, ^^^. All those seem pretty self explanatory, so I won’t go into much detail about the parser itself. But if you’d like to learn more about using scala-parser-combinators the getting started page is a nice starting point.
After parsing, we have our signature mapped into a more approachable form. So let’s look at our application from the user's perspective. If I input a signature, let’s say something like String.(Int) -> Any. What functions do I want to see as the result? In other words what should be the relation between our input signature and the result signatures? Well, the easiest and most intuitive relation would be substitution. So for the given signature anything that can be used in its place should be fine. So a function like drop with a signature String.(Int) -> String is a good fit, since it has the same input types and just a more specific return type. But a function like maxOf (Int.(Int) -> Int) doesn’t fit, because clearly the receiver- Int has nothing to do (in terms of subtyping) with the expected receiver String.
HTTP Client
What would be Inkuire without an easily-accessed, user friendly client? The most intuitive and the simplest to deploy on your own is a RESTful service. Inkuire offers a ready to use JAR container that lets you ship the engine locally or globally without much overhead. Graphic design is not our passion, but we did our best.
You can also try it yourself here.
What if we would like to embed the engine into the documentation itself?
Imagine that: you configure dokka for your own library. Your code is encouraging to use it functional-programming style, maybe has an ArrowKt as a dependency. You would like to ship your documentation as the HTML pages, but the default search bar in dokka’s default template allows you to search by function names. It would be awesome, if users could browse the documentation using signatures as search keys. We thought the same. So we decided to enable that using Scala.js!
Is it even possible?
Well, Scala.js always has been a dark horse of Scala. Many Scala developers remain unaware to these days that Scala.js exists. But it does. And has really good support from community libraries. The idea is: you can transpile your Scala code to JavaScript if all your dependencies can or you depend on stdlib. Luckily, many popular libraries guarantee that compatibility.
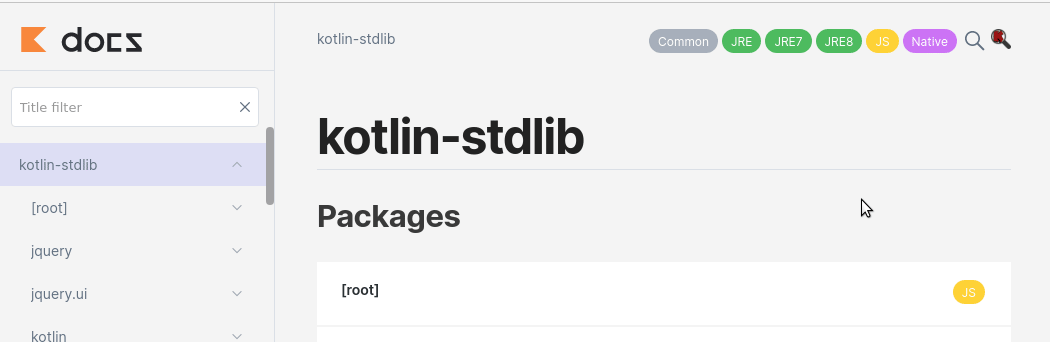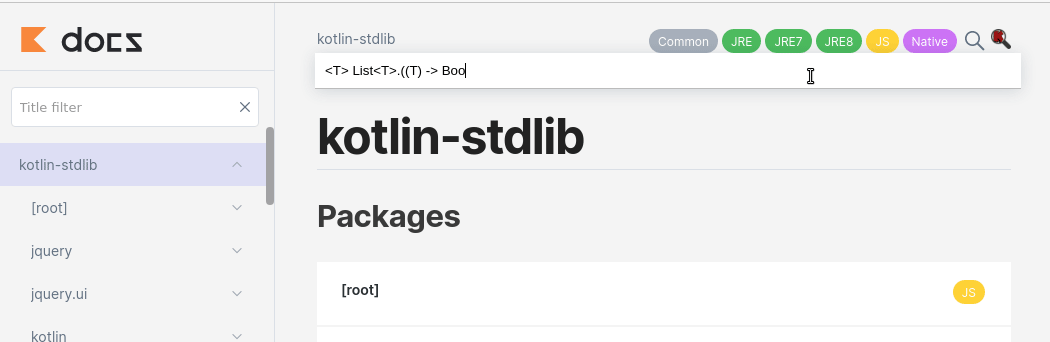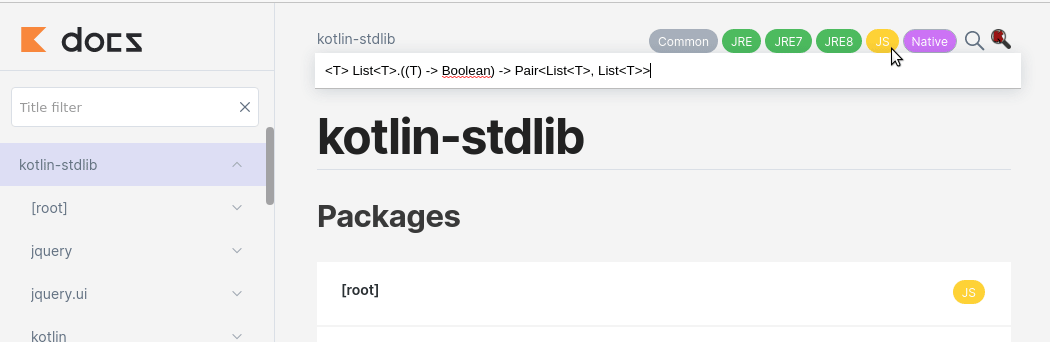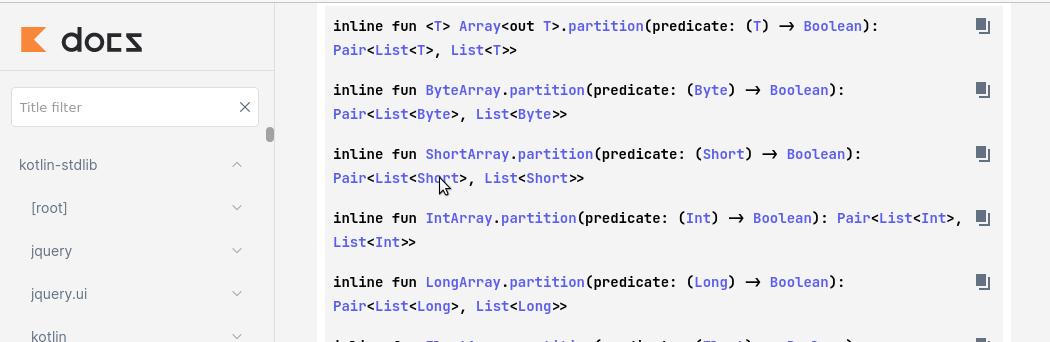
You can try it yourself here.
So how does it work internally?
The querying engine is pure. It has just an input signature and an output list of matching functions. Transpilation to JavaScript is as easy as a piece of cake. The JavaScript obtained from Scala code lets you call the matching function the same way you would call it from standard JVM target. The only thing missing is the way to bind function to the DOM search bar. Luckily, Scala.js provides a DOM API, so you can include all the logic in Scala code without writing a single line of JavaScript by yourself. Isn’t it awesome?
Why Scala.js and not RESTful service?
Why did we decide to transpile the engine code into JavaScript and not use the previously stated RESTful server to delegate calls and present results? Mainly, because we can encapsulate the whole deployment process in one plugin. The user has not to bother with deploying the JAR with the engine. If he could ship docs generated by dokka, he is able to ship them with our plugin attached. This approach also removed the problem with having to update the data for the server with every release. The database is built with documentation, so it will always be in sync with it. The cost of adding the plugin to dokka isn’t that big (memory wise), the JavaScript code itself has only a few MB and e.g. the JVM part of stdlib has 15MB.
Runtime efficiency test of JS and JVM
Is it worth using an engine running in your browser instead of a dedicated JVM? Let’s see. The criteria of the test are: time of engine processing and overall time for the user since he typed the signature till received results. The JVM tests have been conducted using Apache JMeter and JS with Selenium (Chrome runner). The table below shows results:
| Platform | Avg engine processing time | Std engine processing time | Avg ovberall time | Std overall time |
|---|---|---|---|---|
| JVM | 330.26 ms | 26.64 ms | 332 ms | 25.65 ms |
| JS | 1165.57 ms | 100.98 ms | 2170.31 ms | 101.43 ms |
As you can see, the JVM version is about 5 times faster than JS one. The additional 1 second in overall time in JS comes from the debounce time of the input field, so we can detect when the user starts typing. One could think, it’s better to use RESTful service, however, the time latency is so relatively small, it is hard to experience inconvenience from waiting for the results, having the advantage of jumping directly to the exact documentation subpage.
What if I would like to use it myself?
Currently, we do not publish artifacts to remote repositories. If you would like to use Inkuire for your project here source code. Installation guide can be found in readme. Note that Inkuire has two main drawbacks. One is not a fully integrated multiplatform - you have to choose arbitrarily which source sets you would like to query from. Also, there is still the problem with getting a full hierarchy tree of types declared in dependencies. The rule of thumb is the same as with Scala.js: To obtain a full hierarchy tree, you must provide types databases from all dependencies. We know that going recursively deeper in the dependencies tree and generating all types databases is a tedious job, but it’s the only solution available right now. However, using a type database only for a given library will cause engine work heuristicly; it will give true and applicable results, though he won’t see all possible substitutions, and you will not be able to use types that you know are higher in the inheritance tree.
Medium link: https://medium.com/virtuslab/how-to-write-hoogle-for-kotlin-in-scala-and-scala-js-8c98c1c303ff